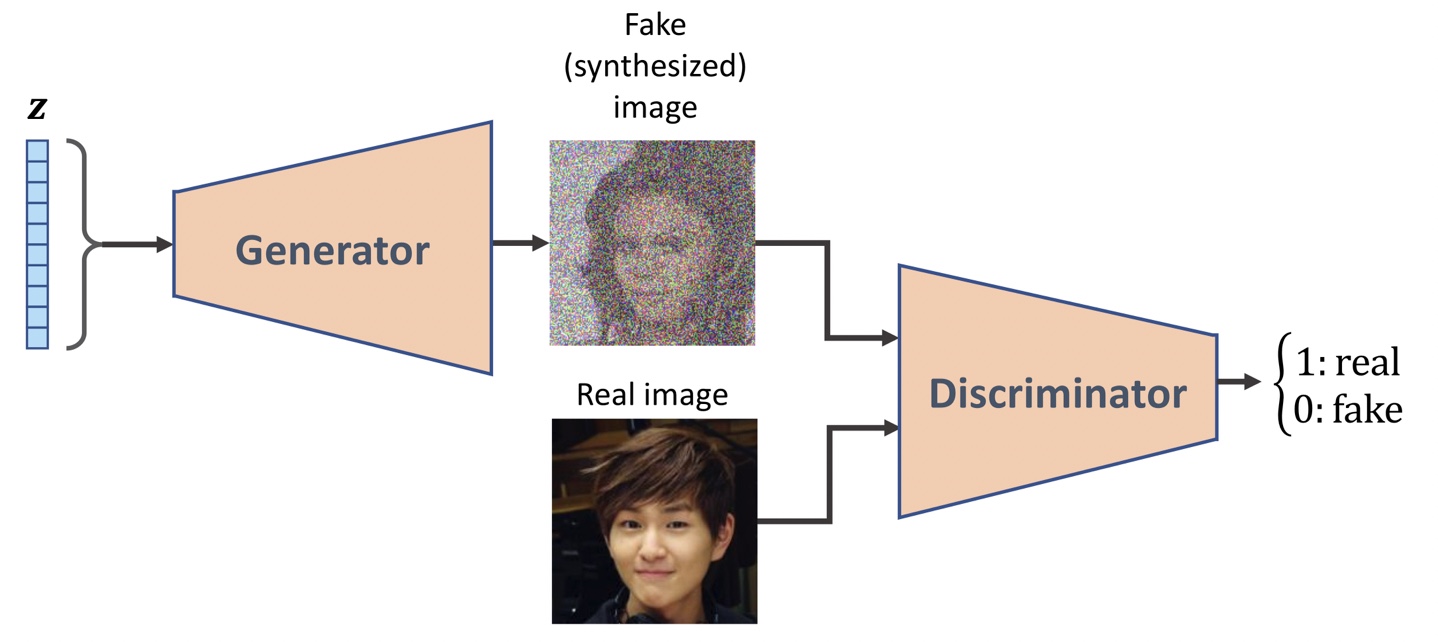
Generator: 생성자, Discriminator: 판별자
알려진 분포에서 샘플링한 랜덤 벡터 z를 입력받아 입력 이미지 x를 생성
생성자(generator, G)
x_^=G(z)
신경망은 랜덤한 가중치로 초기화(학습되기 전에 출력한 이미지는 백색 소음과 비슷하다)
생성한 이미지를 평가하는 함수를 평가함수라고 할 때,
평가함수에서 피드백을 받아서 생성된 이미지의 품질을 높이기 위해서 생성자의 가중치를 수정해야 한다.
(평가함수의 피드백을 기반으로 생성자를 훈련)
이미지 품질을 평가하는 범용적인 평가함수를 만들기 쉽지 않다.
사람은 신경망의 출력을 보고 이미지 품질을 쉽게 평가할 수 있다.
사람의 뇌가 함성 이미지의 품질을 평가할 수 있다면, 비슷한 일을 하는 신경망 모델을 만든 것이 GAN의 아이디어 기본 아이디어이다.
GAN은 생성자와 판별자(discriminator, D)라고 불리는 두개의 신경망으로 구성되어 있다.
판별자를 통해서 진짜 이미지에서 합성 이미지를 감지하는 법을 학습
GAN에서 생성자와 판별자 두 신경망이 동시에 학습되며, 먼저 모델 가중치를 초기화한 후
생성자가 진짜처럼 보이지 않는 두 이미지를 생성한다.
판별자 또한 진짜 이미지와 생성자가 합성한 가짜 이미지를 구분하는 능력이 형편이 없다.
훈련을 통해 두 신경망이 서로 상호 작용을 하면서 향상된다.
두 신경망이 적대적인 게임(adversarial game)을 수행한다.
생성자는 판별자를 속이기 위해 출력을 향상시키도록 학습되며, 판별자는 합성 이미지를 더 잘 감지하도록 훈련된다.
Value function

GAN의 목적함수는 위와 같으며, V를 가치 함수(Value function)이라고 부른다.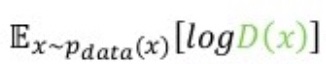
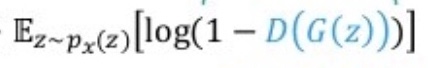
판별자(D)에 대해서는 이 값을 최대화하고 생성자(G)에 대해서는 이 값을 최소화해야한다.
D(x)는 샘플 x가 진짜인지 가짜인지 나타내는 확률이다.
위 식은 데이터 분포(진짜 샘플의 분포)에서 온 샘플에 대한 대괄호 안에 있는 식의 기댓값을 나타낸다.
위 식은 입력 벡터 z에 대한 대괄호 안에 있는 식의 기댓값을 나타낸다.
가치함수의 첫 번째 항은 진짜 샘플에 연관된 손실, 두 번째 항은 가짜 샘플에 연관된 손실이다.
GAN 모델의 훈련 최적화 단계
1. 판별자에 대한 보상을 최대화2. 생성자에 대한 보상을 최소화
GAN은 위의 두 단계를 교대로 수행한다.
- 한 신경망의 가중치를 고정(동결)하고 다른 신경망의 가중치를 훈련
- 두 번째 신경망을 고정하고 첫 번째 신경망을 최적화
ex) 생성자 신경망을 고정할 경우
V를 최대화하는 것이 목적함수가 된다.(판별자는 보상을 최대화 해야한다.)
판별자가 진짜와 가짜를 더 잘 구분하도록 판별자를 최적화
이후 판별자를 고정하고 생성자를 최적화한다.
판별자는 고정되어 있기 때문에 그레이디언트는 두 번째 항만이 기여한다.
min E_z[log(1-D(G(z)))]는 훈련 초기 단계에서 그레이디언트 소실단계가 발생한다.
이와 같은 포화(saturation)을 피하기 위해서 목적함수를 max E_z[log(D(G(z))]로 바꿔어 쓸 수 있다.
(생성자 훈련에서 진짜와 가짜 이미지를 뒤바꾸고, 일반적인 함수 최솟값을 찾는 작업을 수행하는 것과 같다.)
GAN 데이터 레이블
판별자가 이진 분류기(가짜, 진짜 이미지에 대한 클래스 레이블이 각각 0, 1)이면 이진 크로스 엔트로피 손실함수를 사용할 수 있다.
생성자는 판별자가 생성자의 출력을 진짜로 분류하지 않으면, 생성자에게 벌칙을 부여한다.
(생성자의 손실함수를 계사할 때, 생성자의 출력에 대한 레이블을 1로 가정)
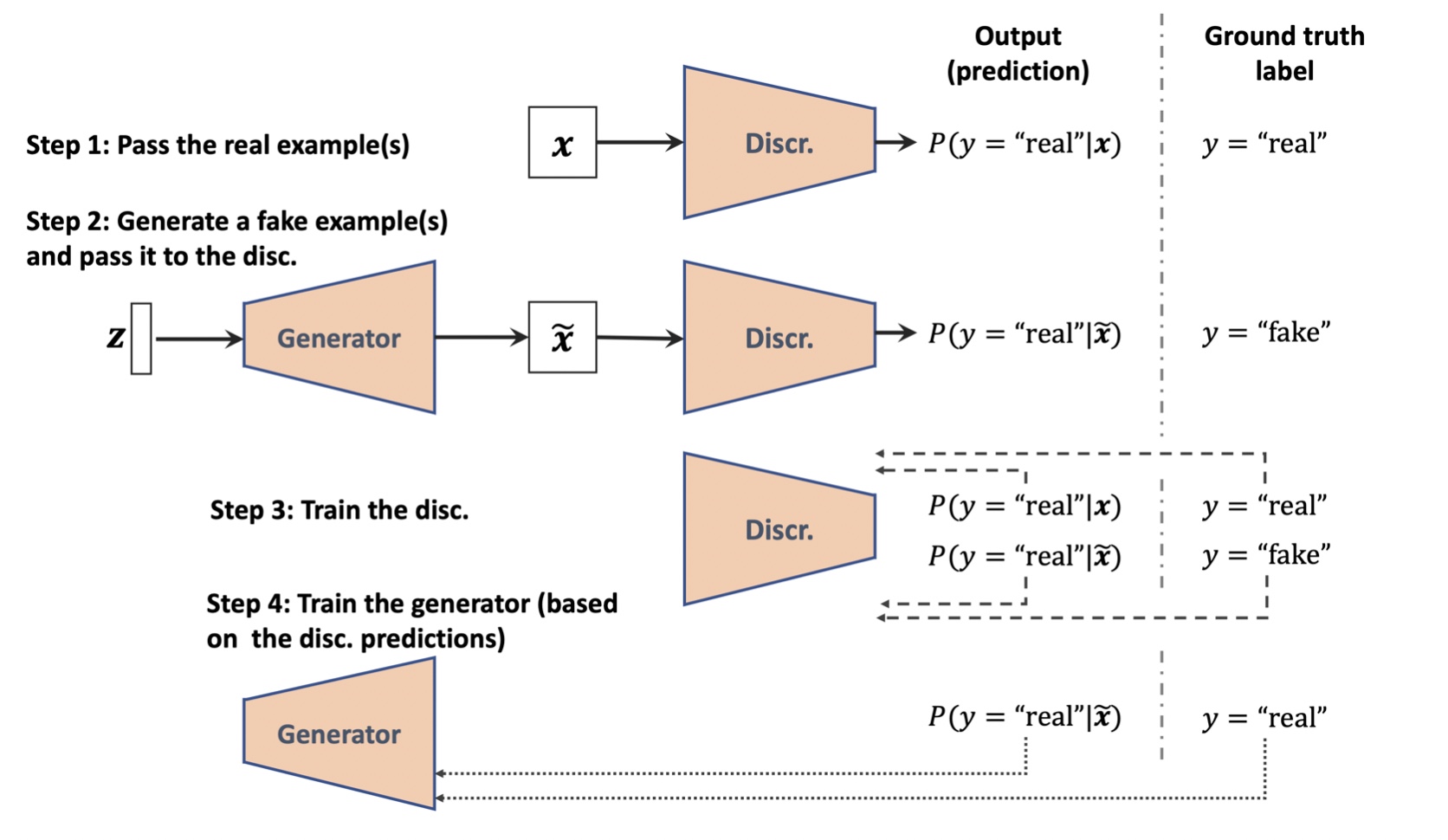
GAN 손실함수에 대한 자세한 내용 참고
머신러닝교과서with파이썬,사이킷런,텐서플로_개정3판pg.724